A U-shaped component is to be formed from three part A, B and C, as shown in the picture below. The length of A is normally distributed with a mean of 10 millimeters and a standard deviation of 0.1 millimeter. The thickness of parts B and C is normally distributed with a mean of 2 millimeters and a standard deviation of 0.05 millimeter. Assume all dimensions are independent.
1. Determine the mean and standard deviation of the length of the gap D.
2. What is the probability that the gap D is less than 5.9 millimeters?
Answers
1. Mean of gap D = 4 millimeters and Standard deviation of gap D = 0.122474487 millimeters
2. The probability of the gap D being less than 5.9 millimeters is virtually 1, or 100%.
1. To determine the mean and standard deviation of the length of the gap D, we first need to find the total length of parts A, B, and C.
The mean of the length A is given as 10 millimeters. Since parts B and C have the same thickness, their combined mean thickness is 2 * 2 = 4 millimeters. So, the total mean length of parts A, B, and C is 10 + 4 = 14 millimeters.
Since the dimensions are independent, we can find the standard deviation of the total length by calculating the square root of the sum of squares of the standard deviations.
Standard deviation of A = 0.1 millimeter
Standard deviation of B and C combined = sqrt(2 * (0.05^2)) = 0.070710678 millimeters
Standard deviation of the total length = sqrt((0.1^2) + (0.070710678^2)) = 0.122474487 millimeters
Now, the length of the gap D is equal to the total length of parts A, B, and C minus the length of part A:
Mean of gap D = Mean of total length - Mean of A = 14 - 10 = 4 millimeters
Standard deviation of gap D = Standard deviation of the total length = 0.122474487 millimeters
2. To find the probability that the gap D is less than 5.9 millimeters, we need to convert the given value to a z-score:
z = (X - μ) / σ
z = (5.9 - 4) / 0.122474487 = 15.525137881
This z-score is extremely large, which means that the probability of the gap D being less than 5.9 millimeters is virtually 1, or 100%.
For more such questions on Probability.
https://brainly.com/question/24297016#
#SPJ11
Related Questions
2. While Amir is looking for Hassan and the blue kite, he runs into two different men who make fun of Hassan. Why
Answers
Amir's search for Hassan and the blue kite occurs in the novel "The Kite Runner" by Khaled Hosseini. The two men Amir encounters mock Hassan primarily because of his Hazara ethnicity, which is a marginalized and discriminated group in Afghanistan.
Hassan's social status is further complicated by the fact that he is Amir's family's servant, emphasizing the existing class differences between them. The novel portrays the social and cultural tensions in Afghanistan during that period, highlighting the disparities between the dominant Pashtun ethnic group, which Amir belongs to, and the Hazara minority. These disparities manifest in various forms of prejudice, including mockery, which further emphasizes the power dynamics at play.
In this particular scene, the men's mockery of Hassan is an attempt to belittle and demean him, thereby reinforcing the status quo that supports their own position within the social hierarchy. Amir's reaction to the situation also sheds light on his internal struggle with loyalty, friendship, and personal identity.
In conclusion, the men mock Hassan due to his Hazara ethnicity and his position as a servant in Amir's household, reflecting the societal prejudices and power imbalances present in Afghanistan during that time.
Know more about hierarchy here:
https://brainly.com/question/31044709
#SPJ11
1.1 Discuss how interactions involving dummy variables, impact on the results and interpretation of a regression model. Use your own example. 1.2 State the problems of using the linear probability model. In addition, briefly explain how some of these problems can be remedied 1.3 Critically assess the goodness-of-fit measures of logit models.
Answers
Interactions involving dummy variables can provide insights into the different effects of independent variables across categories.
1. Dummy variables are binary variables that represent categorical variables in a regression analysis. When interactions are included between dummy variables and other independent variables, it allows for differential effects of the independent variables based on the different levels of the categorical variable.
For example, let's consider a regression model to predict income based on education level and gender. We can include an interaction term between education level (represented by dummy variables for different levels) and gender. This interaction term allows us to examine whether the effect of education level on income differs between males and females. It helps capture any gender-specific differences in the relationship between education and income.
1.2 The linear probability model (LPM) is a common approach to estimate the probability of an event occurring using a linear regression framework. However, it has several problems:
1. The predicted probabilities from the LPM can fall outside the [0, 1] range: Since the LPM does not impose any restrictions on the predicted probabilities, they can sometimes exceed the valid probability range. This violates the assumption of probabilities being bounded between 0 and 1.
2. Heteroscedasticity: The LPM assumes constant error variance across the range of the predictors. However, in practice, the variability of the error term may change with different levels of the predictors, resulting in heteroscedasticity. This violates the assumption of homoscedasticity.
3. Non-linearity: The LPM assumes a linear relationship between the predictors and the probability of the event. However, this may not always be the case, and using a linear model can result in misspecification.
To remedy these problems, an alternative to the LPM is to use logistic regression or probit regression models. These models explicitly model the probability of an event occurring and address the issues mentioned above. They provide predicted probabilities that fall within the valid range of 0 to 1, account for heteroscedasticity, and allow for non-linear relationships between the predictors and the probability of the event.
Learn more about LPM here:
https://brainly.com/question/30890632
#SPJ4
2.6 divided by 97.526
Answers
Answer:
Step-by-step explanation: how do u supposed to divide that???
Answer:
Just put it into a calculator
Step-by-step explanation:
Random variable X has a normal distribution with mean u and standard deviation 2. The pdf f(x) of X satisfies the following conditions: (A) f6 > f(16), (B) f(1)
Answers
we have:
P(X > 6) < 0.0668
We can use the standard normal distribution to find probabilities for a normal distribution with mean u and standard deviation 2. Let Z = (X - u)/2 be the standard normal variable corresponding to X.
(A) Since f(6) > f(16), we have P(X < 6) > P(X < 16). Using the standard normal distribution, we can write this as:
P(Z < (6 - u)/2) > P(Z < (16 - u)/2)
Multiplying both sides by -1 and using the symmetry of the standard normal distribution, we get:
P(Z > (u - 6)/2) < P(Z > (u - 16)/2)
Looking up the standard normal distribution table, we can find the values of the right-hand side probabilities for different values of the argument. For example, if we use a table with z-scores and look up the probability corresponding to z = 1.5, we find that P(Z > 1.5) = 0.0668 (rounded to four decimal places).
Therefore, we have:
P(X > 6) < 0.0668
To know more about probabilities refer here:
https://brainly.com/question/30034780
#SPJ11
Write your answer with an exponent

Answers
Answer:
\( {7}^{12} \)
Step-by-step explanation:
just keep the 7 and add the exponents
Members of the drama club spend $795 on t-shirts and sweatshirts for a play.They purchase 20 more tshirts than sweatshirts.They buy tshirts for $12 each sweatshirt for $25 each. How many tshirts do the drama club buy
Answers
Answer:
The drama club bought 35 t-shirt
Step-by-step explanation:
Let
t-shirt = x
Sweatshirt = y
Total cost = $795
They purchase 20 more tshirts than sweatshirts
x = y + 20
The equation is:
12x + 25y = 795
12(y + 20) + 25y = 795
12y + 240 + 25y = 795
37y = 795 - 240
37y = 555
y = 15
Substitute y = 15 into
x = y + 20
x = 15 + 20
x = 35
t-shirt = 35
Sweatshirt = 15
The drama club bought 35 t-shirt
Chloe will role a numbered die and flip a coin for a probability experiment. The faces of the numbered die are labeled 1 through 6. The coin can land on heads or tails. If Chloe rolls the number cube twice and flips the coin once, how many possible outcomes are there?
Answers
Answer:If Chloe rolls the number cube twice and flips the coin once, there are 2 possible outcomes for the coin flip (heads or tails) and 6 possible outcomes for each roll of the number cube.
To find the total number of possible outcomes, we can use the multiplication principle of counting. The total number of possible outcomes is given by the product of the number of outcomes for each event.
Therefore, the total number of possible outcomes is:
2 x 6 x 6 = 72
So, there are 72 possible outcomes when Chloe rolls the number cube twice and flips the coin once.
Step-by-step explanation:
If an 80 confidence interval and a 90 confidence interval are constructed from the same sample data, the 80 confidence interval will be___________________ the 90 confidence interval.
Answers
The 80% confidence interval will be narrower than the 90% confidence interval when constructed from the same sample data.
If an 80% confidence interval and a 90% confidence interval are constructed from the same sample data, the 80% confidence interval will be narrower than the 90% confidence interval.
To understand why this is the case, we need to know that a confidence interval is a range of values within which we estimate the true population parameter lies. The level of confidence associated with the interval represents the probability that the true parameter falls within that range.
In this scenario, an 80% confidence interval means that there is an 80% probability that the true parameter lies within the interval. On the other hand, a 90% confidence interval means that there is a 90% probability that the true parameter falls within the interval.
To construct a narrower interval, we need to have a higher level of confidence. As the confidence level increases, the range of possible values also widens to accommodate the higher probability. Therefore, the 80% confidence interval will be narrower than the 90% confidence interval.
In conclusion, the 80% confidence interval will be narrower than the 90% confidence interval when constructed from the same sample data.
To know more about confidence interval visit:
brainly.com/question/32546207
#SPJ11
NEED HELP ASAP Please
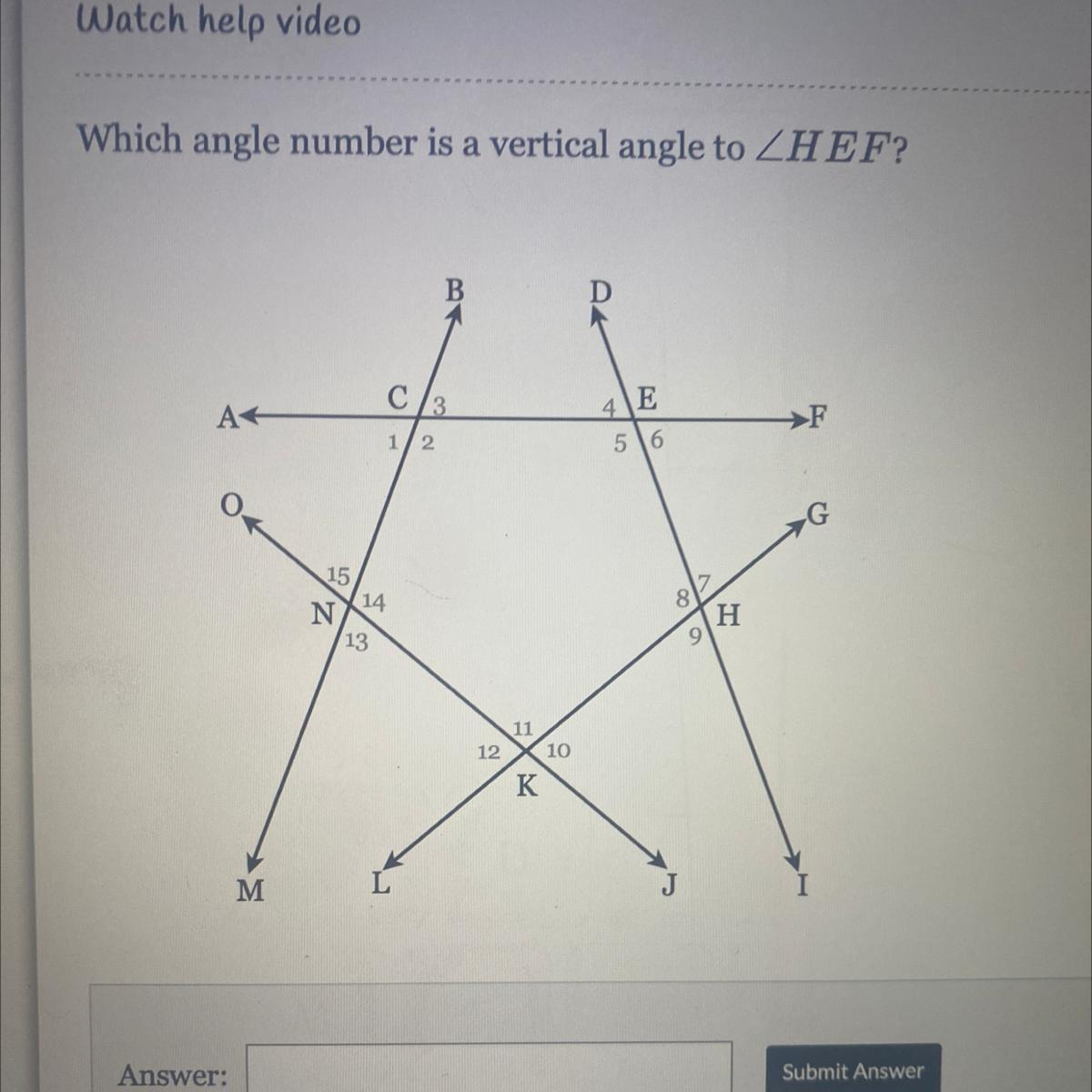
Answers
Answer:
<4
Step-by-step explanation:
Vertical angles are formed by the same lines and share a vertex but are opposite.
< HEF also called <6 is a vertical angle to < 4
HELP Find the sector area of a circle, when m
Sector Area= ____units square
Answers
Step-by-step explanation:
The first thing to do is calculate the dimensions of the pizza box. Based on our data, we know 256 = s2. Solving for s (by taking the square root of both sides), we get 16 = s (or s = 16).
Now, we know that the diameter of the pizza is four inches less than 16 inches. That is, it is 12 inches. Be careful! The area of the circle is given in terms of radius, which is half the diameter, or 6 inches. Therefore, the area of the pizza is π * 62 = 36π in2. If the pizza is 8-slices, one slice is equal to 1/8 of the total pizza or (36π)/8 = 4.5π in2.
The results of inspection of DNA samples taken over the past 10 days are given below. Sample size is 100 Day 1 2 3 4 5 6 7 8 9 10 Defectives 7 9 9 11 7 8 0 11 13 2 The upper and lower 3-sigma control chart limits are: UCL=? LCL=?
Answers
The upper and lower 3-sigma control chart limits for this DNA sample data are UCL = 18.53 and LCL = 0
When we are given data on the DNA samples taken over the past 10 days, we can calculate the upper and lower 3-sigma control chart limits. The sample size is 100, and the defective number of DNA samples is given for each of the ten days.
The 3-sigma control limits for a process control chart can be calculated using the following formula: Upper control limit (UCL) = Mean + (3 × Standard Deviation) and Lower control limit (LCL) = Mean - (3 × Standard Deviation),where the mean is the average value of the data, and the standard deviation is the spread of the data around the mean.
Here, we need to calculate the mean and standard deviation of the defective samples for the past 10 days. The average number of defectives per day (mean) is (7+9+9+11+7+8+0+11+13+2) / 10 = 77 / 10 = 7.7
To calculate the standard deviation, firstly, calculate the variance: variance = sum of the squared differences from the mean divided by the number of samples = \([(7-7.7)^2 + (9-7.7)^2 + ... + (2-7.7)^2] / 10\) ≈ 13.01 2.. Now, take the square root of the variance which gives standard deviation. So, standard deviation = \(\sqrt{13.01\\}\) ≈ 3.61
Using the 3-sigma rule UCL = Mean + (3 * Standard Deviation) = 7.7 + (3 * 3.61) ≈ 18.53 and LCL = Mean - (3 * Standard Deviation) = 7.7 - (3 * 3.61) ≈ -3.13. However, since the LCL cannot be negative, we set it to 0 in this context. So, the upper and lower 3-sigma control chart limits are: UCL = 18.53 LCL = 0
To know more about sample data, refer here
https://brainly.com/question/13219930#
#SPJ11
Explain why kilobytes and terabytes would not be descriptive measurements for the amount of space on an average USB storage device (8 - 256 GB).
Answers
Answer:
The storage capacity of the USB is far greater than Kilobytes, but less than a Terabyte.
Step-by-step explanation:
Need help
(4v-4)° (5v-5)°
Answers
Answer:
20v2−40v+20
Step-by-step explanation:
=(4v+−4)(5v+−5)
=(4v)(5v)+(4v)(−5)+(−4)(5v)+(−4)(−5)
=20v^2−20v−20v+20
= 20v^2-40v+20
You can easily do this by using the FOIL method.
F - first - in this case, 4v and 5v
O - Outside - in this case, 4v and -5
I - Inside - in this case, -4 and 5v
L - Last - In this case, -4 and -5
Then you find the like terms and add them together and then you have your answer which is also in standard form.
Use 6-point bins (94 to 99, 88 to 93, etc.) to make a frequency table for the set of exam scores shown below
83 65 68 79 89 77 77 94 85 75 85 75 71 91 74 89 76 73 67 77 Complete the frequency table below.
Answers
The frequency table reveals that the majority of exam scores fall within the ranges of 76 to 81 and 70 to 75, each containing five scores.
How do the exam scores distribute across the 6-point bins?"To create a frequency table using 6-point bins, we can group the exam scores into the following ranges:
94 to 9988 to 9382 to 8776 to 8170 to 7564 to 69Now, let's count the number of scores falling into each bin:
94 to 99: 1 (1 score falls into this range)
88 to 93: 2 (89 and 91 fall into this range)
82 to 87: 2 (83 and 85 fall into this range)
76 to 81: 5 (79, 77, 77, 76, and 78 fall into this range)
70 to 75: 5 (75, 75, 71, 74, and 73 fall into this range)
64 to 69: 3 (65, 68, and 67 fall into this range)
The frequency table for the set of exam scores is as follows:
Score Range Frequency
94 to 99 1
88 to 93 2
82 to 87 2
76 to 81 5
70 to 75 5
64 to 69 3
Read more about frequency
brainly.com/question/254161
#SPJ4
a courier service company wishes to estimate the proportion of people in various states that will use its services. suppose the true proportion is 0.06. if 221 are sampled, what is the probability that the sample proportion will be greater than 0.1? round your answer to four decimal places.
Answers
The probability that the sample proportion will be 0.104.
What is Probability?
Probability refers to potential. A random event's occurrence is the subject of this area of mathematics. The range of the value is 0 to 1. Mathematics has incorporated probability to forecast the likelihood of various events. The degree to which something has been likely to happen is basically what probability means. You will learn the potential outcomes for just a random experiment using this fundamental theory of probability, which is also applied to the probability distribution. Knowing the total list of answers is necessary before we can calculate the likelihood that a specific event will occur.
Given that
p= 0.06
1 - p = 1 + 0 * 6 = 0 * 94
n = 221
p' = p = 0.06
sigma( p) = \(\sqrt{\frac{P(1 - P))}h{} }\)
= \(\sqrt{\frac{0.06*0.94}{221} }\)
=0.0159
p( p' > 0.1 )=1-p( p' <0.1)
= 1 - p(z < 2.51)
=1- .896
= 0.104
Hence the Probability will be 0.104
Learn more about Probability , by the following link.
https://brainly.com/question/24756209
#SPJ4
asking whether the linear system corresponding to an augmented matrix [a1 a2 a3 b] has a solution amounts to asking whether b is in span {a1, a2, a3}.
Answers
To determine if the linear system corresponding to an augmented matrix [a1 a2 a3 b] has a solution, we can check whether the vector b is in the span of the vectors {a1, a2, a3}.
In linear algebra, the augmented matrix represents a system of linear equations. The columns a1, a2, and a3 correspond to the coefficients of the variables in the system, while the column b represents the constants on the right-hand side of the equations. To check if the system has a solution, we need to determine if the vector b is a linear combination of the vectors a1, a2, and a3.
If the vector b lies in the span of the vectors {a1, a2, a3}, it means that b can be expressed as a linear combination of a1, a2, and a3. In other words, there exist scalars (coefficients) that can be multiplied with a1, a2, and a3 to obtain the vector b. This indicates that there is a solution to the linear system.
On the other hand, if b is not in the span of {a1, a2, a3}, it implies that there is no linear combination of a1, a2, and a3 that can yield the vector b. In this case, the linear system does not have a solution.
Therefore, determining whether the vector b is in the span of {a1, a2, a3} allows us to determine if the linear system corresponding to the augmented matrix [a1 a2 a3 b] has a solution or not.
Learn more about matrix here:
https://brainly.com/question/29132693
#SPJ11
Indigo and her children went into a restaurant and she bought $42 worth of
hamburgers and drinks. Each hamburger costs $5. 50 and each drink costs $2. 25. She
bought a total of 10 hamburgers and drinks altogether. Write a system of equations
that could be used to determine the number of hamburgers and the number of drinks
that Indigo bought. Define the variables that you use to write the system
Answers
Answer:
x+y=10
2.25x+5.50y=42
Extra: 6 hamburgers and 4 drinks
Step-by-step explanation:
x+y=10
2.25x+5.50y=42
x would stand for the drinks and y would stand for the hamburger
I do not know if you want me to solve it or not, but I might as well do so.
To solve it, you could multiply the first equation by 2.25 to get:
2.25x+2.25y=22.5
2.25x+5.50y=42
Now, if you subtract the two systems of equations, you get 3.25y=19.5, where y is equal to 6.
When you plug in 6 for y in the first equation, you should find that x is equal to 4.
In conclusion, Indigo ordered 6 hamburgers and 4 drinks.
OMG YES I WILL BE GIVING A BRAINLIST
pls look at image .

Answers
I don't know, but has anyone gotten the glitch where someone anwnsers your question, then its deleted?
c. Using systematic random sampling, every seventh dealer is selected starting with the fourth dealer in the list. Which dealers are included in the sample
Answers
The dealers included in the sample would be 4th, 11th, 18th, 25th, 32nd, 39th, and so on.
Using systematic random sampling with a sampling interval of seven, starting with the fourth dealer in the list,
the dealers included in the sample would be the fourth, eleventh, eighteenth, twenty-fifth, and so on.
Every seventh dealer after the fourth dealer would be included.
Systematic random sampling involves selecting items from a population at regular intervals using a predetermined pattern.
Here, the sampling interval is seven, which means every seventh dealer will be included in the sample.
To start the sampling process, begin with the fourth dealer in the list.
This dealer is the starting point. Then, select every seventh dealer from that point onwards.
So, the dealers included in the sample will be determined by adding multiples of seven to the starting point.
This ensures that we maintain a consistent interval between the selected dealers.
For example, if the fourth dealer is selected as the starting point, the dealers
included in the sample would be the fourth, eleventh, eighteenth, twenty-fifth, thirty-second, thirty-ninth, and so on.
Each selected dealer is determined by adding seven to the previous selected dealer's position.
By following this systematic approach, every seventh dealer is included in the sample, providing a representative subset of the entire dealer list.
Learn more about sample here
brainly.com/question/31764146
#SPJ4
the question is the picture !!

Answers
The prediction for the winning time in year 11 of the race is given as follows:
2.45 minutes.
How to find the equation of linear regression?To find the regression equation, which is also called called line of best fit or least squares regression equation, we need to insert the points (x,y) in the calculator.
The points for this problem are given as follows:
(1, 5.5), (2, 5), (3, 4.5), (4, 5), (5, 4), (6, 4), (7, 3.8), (8, 3.2).
Hence the equation predicting the winning time after x years is given as follows:
y = -0.29x + 5.69.
Hence the prediction for year 11 is given as follows:
y = -0.29(11) + 5.69
y = 2.45 minutes. (rounded).
More can be learned about linear regression at https://brainly.com/question/29613968
#SPJ1
Judy just calculated the standard deviation for a project she is working on. The value for the standard deviation is a small number. What does this represent?
The data is spread far from the mean.
The data is spread close to the mean.
The data is spread equal to the mean.
None of these choices are correct.
Answers
Answer: b) The data is spread close to the mean
Step-by-step explanation: Theoretically, when the standard deviation of a statistical data is large or high, it simply means that the values in such statistical data set are farther away from the mean, On the other hand when the standard deviation is small or low, it simply means that the values of such statistical data are close to the mean of those data on average.
Therefore Judy's low standard deviation for her project simply indicates that her statistical data set is spread close to the mean.
A school had 1 200 students last year and only 1 080 students this year.
What was the percent decrease in the number of students?
Answers
Answer:The percentage decrease in the number of students is -10%.
Given that,
The school has 1,200 students last year.
And, this year it is 1,080.
Based on the above information, the calculation is as follows:
Therefore we can conclude that the percentage decrease in the number of students is -10%.
Step-by-step explanation: noice
HELP me please Show work tooo

Answers
Answer:
45 degrees
Step-by-step explanation:
180-(105+30)
180-135=45
Answer: 45
Step-by-step explanation:
The line is already 180
All the angle are vertical angles also so they are congruent.
Add 105 and 30
105+30=135
Now subtract
180-135
=45
Evaluate each of the expressions below using the given value.

Answers
Answer:
23
Step-by-step explanation:
2a/3+13
Because a=15, we can substite a for 15...
2(15)/3+13
Solve...
30/3+13
10+13
23
The answer is 23.
Find the number if 5/6 of it is 55.
Answers
Answer:
The unknown number is 66.
Step-by-step explanation:
We know that we need to find the number that is 55 when calculated as 5/6 or the whole number. First, we must divide 55 by 5.
55 ÷ 5 = 11
This means that 1/6 of the unknown number is 11.
Now, let's multiply 11 by 6.
11 x 6 = 66
Therefore, the unknown number is 66.
Hope this helps! :)
Another number of the given question is 66
Given that;Product of two given number = 55
One number = 5/6
Find:Another number
Computation:Product of two given number = One number × Another number
n × 5/6 = 55
n = [55][6] / 5
n = 66
Another number = 66
Learn more:https://brainly.com/question/10747608?referrer=searchResults
god help me.. this is so hard..

Answers
Answer:
this is it
Step-by-step explanation:
whats the mean and median and range for 12 , 4 , -2 , 0 , 9 , -2 , 1 , 7 , 8 , 2
Answers
Mean: 4.7
Median: 3
Range: 14
A 4.5-kW resistance heater runs for 6 hours per day for a 30 day period. If the cost of electricity is the average price in Massachusetts, how much will it cost ($) to run the resistance heater
Answers
It will cost $186.30 to run the resistance heater for 30 days with the given conditions.
Given data:
Power consumed by the resistance heater = 4.5 kW
Running time = 6 hours/day
Period of running = 30 days
Cost of electricity = Average price in Massachusetts
To calculate the total energy consumption during this time period,
we use the formula below:
Energy = Power × Time
Energy consumed in 6 hours
= 4.5 kW × 6 hours
= 27 kWh/day
Total energy consumed in 30 days
= 27 kWh/day × 30 days
= 810 kWh
To calculate the cost of running the resistance heater, we use the formula below:
Cost = Energy × Cost per unit of electricity
Cost of electricity per unit in Massachusetts is assumed to be $0.23/kWh
Cost of running the resistance heater
= 810 kWh × $0.23/kWh
= $186.30
Therefore, it will cost $186.30 to run the resistance heater for 30 days with the given conditions.
To know more about resistance visit:
https://brainly.com/question/32301085
#SPJ11
if q is the point x, 4 3 − x , find the slope of the secant line pq (correct to six decimal places) for the following values of x.
Answers
You can find the slope of the secant line PQ for other values of x by substituting them into the expression for the slope:
For x = 2:
slope = -1 / (3 - 2(2))
slope = -1 / (3 - 4)
slope = -1 / (-1)
slope = 1
To find the slope of the secant line PQ, we need two points on the line: P(x, 4) and Q(3 - x, 3).
The slope of a line passing through two points (x1, y1) and (x2, y2) is given by the formula:
slope = (y2 - y1) / (x2 - x1)
In this case, the coordinates of P are (x, 4) and the coordinates of Q are (3 - x, 3). Plugging these values into the slope formula, we have:
slope = (3 - 4) / (3 - x - x)
slope = -1 / (3 - 2x)
To find the slope of the secant line for different values of x, we substitute those values into the expression for the slope.
For example, if x = 1, the slope of the secant line PQ is:
slope = -1 / (3 - 2(1))
slope = -1 / (3 - 2)
slope = -1 / 1
slope = -1
Similarly, you can find the slope of the secant line PQ for other values of x by substituting them into the expression for the slope:
For x = 2:
slope = -1 / (3 - 2(2))
slope = -1 / (3 - 4)
slope = -1 / (-1)
slope = 1
And so on, you can calculate the slope of the secant line for different values of x.
Learn more about expression from
brainly.com/question/1859113
#SPJ11
HELP PLSSS THIS IS HARD SOMEONE

Answers
Answer:
(10,-2.5), (8,-4), (-1,0.5)
Step-by-step explanation:
x-2=8, 2y+3=-2 --> x=10, y=-2.5 --> (10,-2.5) is in the domain.
x-2=6, 2y+3=-5 --> x=8, y=-4 --> (8,-4) is in the domain.
x-2=-3, 2y+3=4 --> x=-1, y=.5 --> (-1,.5) is in the domain.