HELP URGENT!! the data set for a random sample of 10 soccer players heights compared to their shoe sizes is summarized in the table.
questions included in the photo.

Answers
Part A: The equation of least squares regression line is
ŷ = 0.4684X + 64.69888
Part B: The residual that we have here is - 1.382
Part C: Residual refers to the difference between the observed value and the predicted value
How to solve for the residualSum of X = 102.5
Sum of Y = 695
Mean X = 10.25
Mean Y = 69.5
Sum of squares (SSX) = 33.625
Sum of products (SP) = 15.75
Regression Equation = ŷ = bX + a
b = SP/SSX = 15.75/33.63 = 0.4684
a = MY - bMX = 69.5 - (0.47*10.25) = 64.69888
ŷ = 0.4684X + 64.69888
Residual = observed - predicted
The observed = 68
The predicted = 0.4684 x 10 + 64.69888
= 4.684 + 64.69888
= 69.382
residual = 68 - 69.382
= -1.38
Read more on random sample here :
https://brainly.com/question/17831271
#SPJ1
Related Questions
find the value of each variable angle a, angle b, angle c, and angle d outside of a circle is 43 degrees
Answers
Without any additional information about the intercepted arcs or the relationship between the angles, we cannot determine their exact values.
Given that angle d outside of a circle is 43 degrees, we can use the following properties of angles in circles to find the values of angle a, angle b, and angle c:
1. Inscribed Angle: The measure of an inscribed angle is half the measure of its intercepted arc.
2. Central Angle: The measure of a central angle is equal to the measure of its intercepted arc.
3. External Angle: The measure of an external angle is half the difference between the measures of its intercepted arcs.
Using these properties, we can find the value of angle a, angle b, and angle c. However, Please provide more information about the angles' relationships or the intercepted arcs.
To learn more about : values
https://brainly.com/question/843074
#SPJ11
As monte carlo simulation is essentially statistical sampling, the larger the number of trials used, the more precise is the result.
a. True
b. False
Answers
True, Monte Carlo simulation is used for statistical sampling where larger number of trials are used for the precise result.
Step by Step Explanation:
Monte Carlo simulation is a mathematical technique or statistical sampling which is used to predict all possible outcomes of any uncertain event.The larger the number of trials more is the accuracy as it is based on the past data to predict the future outcomes.example : For the prediction of first month sale of any new launch product you can revise more number of old data.It help to calculate probability more accurately.Therefore, it is true to have more number of trials in Monte Carlo simulation statistical sampling for precise result.
Learn more about statistical sampling here
brainly.com/question/29490427
#SPJ4
7.
NOT TO
SCALE
8.
Р
С
B
In the diagram. PQ is parallel to BC.
APB and AQC are straight lines.
PQ = 8 cm, BC = 10 cm and AB = 9 cm.
Calculate PB

Answers
Answer:
PB = 1.8
Step-by-step explanation:
PQ = 8 cm, BC = 10 cm and AB = 9 cm
∆ABC is similar to ∆APQ.
Therefore:
\( \frac{AB}{AP} = \frac{BC}{PQ} \)
Plug in the values
\( \frac{9}{AP} = \frac{10}{8} \)
Cross multiply
AP × 10 = 8 × 9
AP × 10 = 72
Divide both sides by 10
AP = 7.2
PB = AB - AP
PB = 9 - 7.2
PB = 1.8
suppose the real risk-free rate is 2.50% and the future rate of inflation is expected to be constant at 2.80%. what rate of return would you expect on a 5-year treasury security, assuming the pure expectations theory is valid? disregard cross-product terms, i.e., if averaging is required, use the arithmetic average.
Answers
5.30 % rate of return would you expect on a 5-year treasury security, assuming the pure expectations theory is valid.
Real and nominal interest rates: what are they?To reflect the true cost and purchasing power of money that is borrowed or invested, an interest rate is called a real interest rate that has been adjusted for inflation. The nominal interest rate depicts the cost of money and reflects the state of the market. A good's nominal value is its price in terms of money. Its value in relation to another good, service, or collection of goods is what determines its true worth. Given that it is the current interest rate in the economy, it is frequently referred to as the market interest rate (usually charged by banks and other institutions). Depending on the bank or the type of loans or deposits, this nominal interest rate may be 8%, 10%, or 12%.
Nominal interest rate = Real interest rate + Inflation rate
= 2.5% + 2.8%
= 5.30%
Learn more about the Nominal interest rate here: https://brainly.com/question/25877453
#SPJ1
A small accounting firm handles the accounts of 100 clients. Suppose 5% of the accounts have an error. If random sample of 20 of those clients' accounts are randomly selected and audited for accuracy, which of the following statements about p is true?
A. The mean of p is 0.20 and the variance of p is 0.0016.
B. The mu hat p =0.05 and sigma hat p =0.01959.
C. The mu hat p =0.05 and sigma hat p =0.02179 .
D. We cannot determine the mean and standard deviation of p since np and n(1 - p) are not both > 10
Answers
The question asks which statement about the proportion of accounts with errors, denoted as p, is true. The correct statement is Option B: The sample proportion, mu-hat p, is equal to 0.05, and the sample standard deviation of p, sigma-hat p, is equal to 0.01959.
The proportion p represents the probability of an account having an error. To determine the mean and variance of p, we can use the properties of a binomial distribution. In this case, since the sample size (20) is sufficiently large and the underlying population is large (100 clients), we can approximate the binomial distribution with a normal distribution.
Option A states that the mean of p is 0.20 and the variance of p is 0.0016. However, this is incorrect. The mean of p should be equal to the population proportion, which is 0.05, not 0.20. Therefore, Option A is incorrect.
Option B states that the sample proportion, denoted as p-hat (mu-hat p), is equal to 0.05 and the sample standard deviation of p-hat (sigma-hat p) is 0.01959. This is the correct statement. When a random sample is taken from a population, the sample proportion is an unbiased estimator of the population proportion. The standard deviation of the sample proportion can be calculated using the formula sqrt((p(1-p))/n), where p is the population proportion and n is the sample size.
Option C states a different value for the sample standard deviation of p-hat, which is incorrect.
Option D suggests that we cannot determine the mean and standard deviation of p because np and n(1-p) are not both greater than 10. However, this is not a requirement for determining the mean and standard deviation of p. As mentioned earlier, the normal approximation can be used when the sample size is large, and the mean and standard deviation can be calculated accordingly.
Therefore, the correct statement is Option B: The sample proportion, mu-hat p, is equal to 0.05, and the sample standard deviation of p, sigma-hat p, is equal to 0.01959.
To learn more about binomial distribution, click here:
brainly.com/question/29163389
#SPJ11
(DESPERATE PLEASE HURRY)
question down below
please show the work

Answers
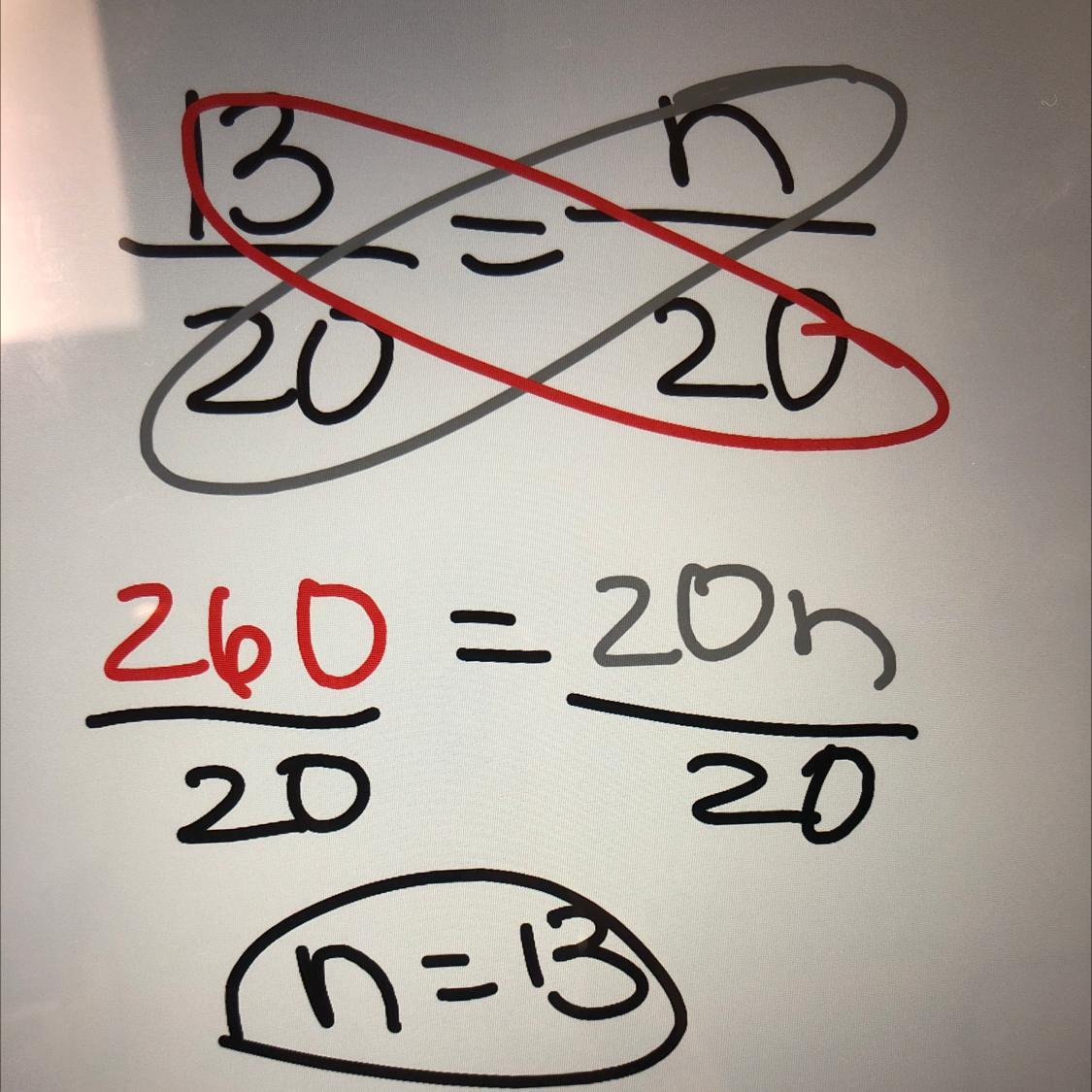
1. Which of the following belongs in the first column of a formal proof?
explanations
statements
A. Explanation
B. Statement
C. Theorems
D. Reason
Answers
Answer:
i believe the answer would be c)theorems
Step-by-step explanation:
sorry if im wrong
51. The optimistic time for completion of Activity " \( X \) " on a PERT chart was 6 hours, the most likely time was for this same activity was 9 hours and the pessimistic time was 12 hours. Using the
Answers
The expected time for completion of Activity "X" on a PERT chart is 9 hours.
PERT analysis is a project management technique that is used to evaluate and analyze the tasks involved in finishing a project. It makes use of 3 duration estimates: optimistic, pessimistic, and most likely times to calculate the expected duration of each activity. These estimates are used to analyze the critical path, slack time, and schedule of the project.
Let's calculate the expected time for completion of Activity "X" on a PERT chart using the given estimates:
Optimistic time (O) = 6 hours
Most likely time (M) = 9 hours
Pessimistic time (P) = 12 hours
Expected time (TE) = [O + 4M + P] ÷ 6= [6 + 4(9) + 12] ÷ 6= [6 + 36 + 12] ÷ 6= 54 ÷ 6= 9
Know more about PERT here:
https://brainly.com/question/14919997
#SPJ11
Are these triangles similar

Answers
Answer: No
Step-by-step explanation:
The ratio of the lengths of the shortest sides is \(\frac{6}{4}=\frac{3}{2}\).
The ratio of the lengths of the longest sides is \(\frac{10}{7}\).
Since these ratios are not equal, the triangles are not similar.
In summer2021, electric power at peak usage times costs about 0.64 $/kWh ≈ 1.8 × 10−7 $/J. An ordi-
nary electrically-powered device in a home might operateat 110 V and 0.12 A. What is the cost per second to power
such a circuit during the peak usage period?
Answers
The cost per second to power such a circuit during the peak usage period is approximately \(2.376 x 10^-6\)$/s. The cost per second to power the circuit during the peak usage period can be calculated using the following steps:
Calculate the power consumption of the device-The power consumption of the device can be calculated using the formula: Power = Voltage x Current. P = V x I, Substituting the given values:
P = 110V x 0.12A
= 13.2 W
Calculate the cost per second-The cost per second can be calculated using the formula:
Cost per second = Power x Cost per Joule
C = P x CC
= 13.2 W x 1.8 x \(10^-7\) $/J
≈ 2.376 x 10^-6 $/s
Therefore, the cost per second to power such a circuit during the peak usage period is approximately 2.376 x\(10^-6\) $/s.
To know more about Power consumption visit-
brainly.com/question/32435602
#SPJ11
Find the exact length of the third side.
4
2
Answers
Answer:
Step-by-step explanation:
4-2<x<4+2
2<x<6
x = 3, 4 or 5
i assume u r talking about triangle
Look at the image below. Identify the coordinates for point X, so that the ratio of AX : XB = 5 : 4
Answers
The coordinates of X that partitions XY in the ratio 5 to 4 include the following: X (-1.6, -7).
How to determine the coordinates of point X?In this scenario, line ratio would be used to determine the coordinates of the point X on the directed line segment AB that partitions the segment into a ratio of 5 to 4.
In Mathematics and Geometry, line ratio can be used to determine the coordinates of X and this is modeled by this mathematical equation:
M(x, y) = [(mx₂ + nx₁)/(m + n)], [(my₂ + ny₁)/(m + n)]
By substituting the given parameters into the formula for line ratio, we have;
M(x, y) = [(5(2) + 4(-6))/(5 + 4)], [(5(-11) + 4(-2))/(5 + 4)]
M(x, y) = [(10 - 24)/(9)], [(-55 - 8)/9]
M(x, y) = [-14/9], [(-63)/9]
M(x, y) = (-1.6, -7)
Read more on line ratio here: brainly.com/question/14457392
#SPJ1
Missing information:
The question is incomplete and the complete question is shown in the attached picture.

Testing more properties of the Cobb-Douglas utility function Check if the Cobb-Douglas utility function u(x
1
,x
2
)=x
i
α
x
2
β
, where α,β>0, satisfies the following properties: (a) local nonsatiation, (b) decreasing marginal utility for both goods 1 and 2, (c) quasi-concavity, and (d) homotheticity.
Answers
The Cobb-Douglas utility function satisfies the properties of local non-satiation, decreasing marginal utility for both goods, quasi-concavity, and homotheticity.
The Cobb-Douglas utility function u(x1, x2) = xi^(α) * x2^(β), where α and β are both greater than zero, satisfies the following properties:
(a) Local non-satiation:
This property states that at each point of the consumption set, there is always another bundle that is arbitrarily close and strictly preferred. Thus, the function has local non-satiation.
(b) Decreasing marginal utility for both goods 1 and 2: The marginal utility of a good measures the utility obtained by consuming one more unit of it. The marginal utility of x1 can be obtained as:
MU1 = α * xi^(α−1) * x2^(β)
The marginal utility of x2 can be obtained as:
MU2 = β * xi^(α) * x2^(β−1)
Therefore, both marginal utilities are decreasing in x1 and x2, satisfying this property.
(c) Quasi-concavity:
The Cobb-Douglas function is quasi-concave. This means that the upper contour set of any level set of the function is convex. This can be proved by taking the second partial derivative of the function and checking whether it is negative or not.
(d) Homotheticity:
The Cobb-Douglas function is homothetic. This means that its shape is independent of the total level of utility. The proof can be achieved by checking whether the function is homogeneous of degree one or not. This is true, since multiplying the inputs by any positive scalar λ leads to a proportional increase in the output.
In conclusion, the Cobb-Douglas utility function satisfies all four properties - local non-satiation, decreasing marginal utility for both goods 1 and 2, quasi-concavity, and homotheticity.
Learn More About marginal utility from the below link:
https://brainly.com/question/15050855
#SPJ11
A backpack that normally sells for $40 is on sale for $38. Find the percent of increase or decrease. *20 POINTS* (PLS SHOW WORK)
Answers
Answer:mj,bhvb n
mnbnmb mbnmbnb
Step-by-step explanation:
Find the solution of the initial value problem. y ''+2y'+2y = h(t), y(0) = 0, y' (0) = 1;
h(t) = 1, π ≤ t < 2π
0, 0 ≤ t < π and t ≥ 2π.
Answers
The obtained values of the initial value problem are:
y(t) = e^(-t)*sin(t) + 1/2, 0 ≤ t < π
y(t) = e^(-t)*sin(t), π ≤ t < 2π
y(t) = e^(-t)*sin(t) + 1/2, t ≥ 2π
To solve the initial value problem, we first need to find the homogeneous solution to the differential equation y'' + 2y' + 2y = 0. The characteristic equation for this differential equation is r^2 + 2r + 2 = 0, which has complex roots given by r = -1 ± i. Thus, the homogeneous solution is of the form:
y_h(t) = e^(-t)(c1cos(t) + c2sin(t))
where c1 and c2 are constants determined by the initial conditions. Using y(0) = 0, we have:
y_h(0) = c1 = 0
Using y'(0) = 1, we have:
y'_h(t) = -e^(-t)cos(t) + e^(-t)(-sin(t))
y'_h(0) = -1c1 + 0c2 = -1
Thus, c2 = 1, and the homogeneous solution is:
y_h(t) = e^(-t)*sin(t)
Now we need to find the particular solution for the non-homogeneous differential equation y'' + 2y' + 2y = h(t), where h(t) is given by:
h(t) = 1, π ≤ t < 2π
h(t) = 0, 0 ≤ t < π and t ≥ 2π
Since h(t) is piecewise-defined, we will find the particular solution separately for each interval.
For the interval 0 ≤ t < π and t ≥ 2π, the right-hand side of the differential equation is zero, so the particular solution is y_p(t) = 0.
For the interval π ≤ t < 2π, we can use the method of undetermined coefficients to find the particular solution.
Since the right-hand side is a constant function, we assume a particular solution of the form y_p(t) = A, where A is a constant. Plugging this into the differential equation, we get:
0 + 0 + 2A = 1
Thus, A = 1/2, and the particular solution for this interval is y_p(t) = 1/2.
Therefore, the general solution for the initial value problem is:
y(t) = y_h(t) + y_p(t) = e^(-t)*sin(t) + 1/2, 0 ≤ t < π and t ≥ 2π
y(t) = e^(-t)*sin(t), π ≤ t < 2π
Click the below link, to learn more about Homogenous solutions to equations:
https://brainly.com/question/16921211
#SPJ11
The length and
the width of a
rectangle are 20
yards and a yard
respectively.
Determine the
perimeter of
rectanble.
Answers
Answer:
42 yards
Step-by-step explanation
There are 4 sides to a rectangle. 2 lengths, and 2 widths. That means that you multiply both values by 2 and then add them together, so 40 + 2. A more basic way to think of it is 20+20+1+1. Therefore, the perimeter is 41 yards.
Mock June 22 1F Overview Question Progress Exam Paper Progress 42/80 Marks 10 Eric throws a biased coin 10 times. He gets 3 Tails. Sue throws the same coin 50 times. She gets 20 Tails. 10 Grade For This Paper U 3 Aadi is going to throw the coin once. (i) Which one of the following statements is correct about the probability of Aadi getting Tails? 2/5 (ii) Use Eric's and Sue's results to work out an estimate for the probability that Aadi will get Tails. Write your fraction in the form a/b 13 A Sue's estimate is best because she throws it 50 times. B Sue's estimate is best because she gets more Tails. C Sue's estimate is best because she throws it more times than Eric (1) (1) 15 Total marks: 2 16 17
Answers
The best estimate for the probability of getting tails is given as follows:
C Sue's estimate is best because she throws it more times than Eric.
How to obtain the probabilities?A probability is obtained as the division of the number of desired outcomes by the number of total outcomes.
For this problem we calculate an experimental probability, as the outcomes are obtained from the previous trials of Eric and Sue.
The higher the number of trials, the closer the experimental probability is to the theoretical probability, meaning that the correct option is given by option C.
More can be learned about probabilities at https://brainly.com/question/27899440
#SPJ1
According to the text, what are two of Earth’s wind patterns? Choose two
a jet streams—high, narrow bands of fast-moving air
b cold front—cold air that advances as warm air retreats
c chinook—warm wind associated with the Rocky Mountains
d warm front—warm air that advances as cold air retreats
Answers
Answer:
Warm front and Cold Front I believe.
Step-by-step explanation:
Answer:
a or d
Step-by-step explanation:
both makes sense
Jump ropes are given out during gym class. A student has a 1/2 chance of getting a red jump rope and a 1/8 chance of getting a green jump rope. Meg is given a jump rope
What is the probability that Meg gets a red or green jump rope?
Answers
Find the lowest common denominator for the following fractions.

Answers
Answer:
The answer is 6. It is the lowest number that 2 and 3 can go into without leaving a remainder.
Solve the equation
4×=68
A.64
B.72
C.12
D.17
Answers
. True or false. Randomization distributions are centered at the value where the null is true. True False
Answers
False. Randomization distributions are centered at the value where the null is false. This distinction is important in hypothesis testing as it helps determine the statistical significance of observed differences or effects.
Randomization distributions are generated through permutation tests, which involve random shuffling of data points between groups. In hypothesis testing, the null hypothesis assumes that there is no difference between groups or no effect of a treatment. The alternative hypothesis suggests otherwise.
The randomization distribution is created by repeatedly shuffling the data and calculating a test statistic based on the null hypothesis. This distribution represents the expected outcomes if the null hypothesis is true. Therefore, the randomization distributions are centered at the value where the null is false, as they capture the potential differences or effects between groups.
In summary, randomization distributions are not centered at the value where the null is true; rather, they are centered at the value where the null is false. This distinction is important in hypothesis testing as it helps determine the statistical significance of observed differences or effects.
To know more about hypothesis visit:
https://brainly.com/question/32562440
#SPJ11
Please help me with number 9 ASAP

Answers
Hey pls answer this (25)

Answers
The congruent triangles in this problem are given as follows:
Triangles A and B.
What are congruent figures?Two figures are classified as congruent if their side lengths are the same.
If we rotate triangle B 180º over it's base, we have that it will have a similar format to triangle A, and also with the same side lengths.
Hence the congruent triangles in this problem are given as follows:
Triangles A and B.
With triangle C, no rotation would make it like A and B, with the same side lengths, hence it is not congruent to any of the triangles in this problem.
More can be learned about congruence of figures at https://brainly.com/question/1675117
#SPJ1
What is 3/4 of 40?
This is 5th grade level it’s for my sister and I don’t really remember this.
Answers
Answer:
30
Step-by-step explanation:
there's a few different ways of solving this:
1)3/4 = 0.75
0.75 * 40
30
2)
divide 40 by 4 and then multiply by 3
40/4
10
10 * 3
30
3)
\(\frac{3}{4} *\frac{40}{1}\)
the 4 and 40 cancel out
\(\frac{3}{1}* \frac{10}{1}\)
3 * 10 = 30
\(\frac{30}{1}\) = 30
The distance between Chembur, Mumbai and Kothrud, Pune is 150 km. I start driving from Kothrud at 7:00 am and traveled towards Chembur at 80 km/hr. My wife starts driving from Chembur at 7:30 am and traveled towards Kothrud at 70 km/hr. At what time will we cross each other?
Answers
According to the distance, you and your wife will cross each other at 8:14 am.
Now, we can use the formula to calculate the time taken by both of you to cover the distance. We know that you start driving from Kothrud at 7:00 am and your speed is 80 km/hr. Let's assume that you both meet after t hours. Then, your distance covered can be calculated as:
Distance covered by you = Speed x Time = 80t km
Similarly, your wife starts driving from Chembur at 7:30 am and her speed is 70 km/hr. By the time she reaches the meeting point, she would have driven for (t-0.5) hours. Her distance covered can be calculated as:
Distance covered by your wife = Speed x Time = 70(t-0.5) km
Now, we know that the total distance covered by both of you is equal to the distance between Chembur and Kothrud, which is 150 km. Therefore, we can equate the two distances to find the value of t:
Distance covered by you + Distance covered by your wife = 150
80t + 70(t-0.5) = 150
150t = 185
t = 1.23 hours
So, you both will meet after 1.23 hours from the time you started driving. But we need to convert this to the actual time. Since you started at 7:00 am and your meeting time is after 1.23 hours, your meeting time will be:
7:00 am + 1 hour and 14 minutes = 8:14 am
To know more about distance here
https://brainly.com/question/4199102
#SPJ4
Which of the following statements are true regarding the margin of error? Select all correct options. A large confidence level requires a small value of 2*, Being more confident increasing confidence level) will yield a larger margin of error The margin of error is not influenced by the sampling distribution's standard deviation Selecting a larger SRS from the population will yield a smaller margin of error.
Answers
The following statements are true regarding the margin of error: Being more confident (increasing confidence level) will yield a larger margin of error and selecting a larger SRS from the population will yield a smaller margin of error.
A margin of error (MOE) is the degree of inaccuracy in estimating a population's true proportion or mean by analyzing a sample dataset. It represents the uncertainty or confidence level of a poll's findings. It is a critical element in political polls, scientific studies, and marketing research. The accuracy of the findings is expressed in the margin of error, which is given as a percentage. The standard deviation of the sampling distribution, not the standard deviation of the population, determines the margin of error. As a result, selecting a larger sample size, the standard deviation decreases, and the margin of error decreases. Therefore, selecting a larger SRS from the population will yield a smaller margin of error. Confidence intervals are used to determine the margin of error, and increasing the confidence level will result in a larger margin of error. As a result, being more confident (increasing confidence level) will yield a larger margin of error.
Thus, the correct options are (B) and (D). Option (A) is incorrect because a large confidence level requires a large value of 2*. Option (C) is incorrect because the margin of error is influenced by the standard deviation of the sampling distribution.
Learn more about margin of error visit:
brainly.com/question/29419047
#SPJ11
in one recent year, 630 different pitchers pitched to at least one batter in a major-league baseball game. if the probability of a randomly-selected person being left-handed is 0.117, how many of those pitchers would you expect to be left-handed? round to the nearest whole person.
Answers
You would expect 73 left-handed pitchers out of the 630 total pitchers in a major-league baseball game in one recent year.
The probability of a randomly selected person being left-handed is 0.117. Using this information, the expected number of left-handed pitchers in a group of 630 can be determined using the formula:
Expected Value = (Probability of Event) * (Number of Trials)
Expected Value = (0.117) * (630)
Expected Value = 73.31
Therefore, you would expect 73 left-handed pitchers out of the 630 total pitchers in a major-league baseball game in one recent year.
Learn more about probability here:
https://brainly.com/question/30034780
#SPJ4
with a sampling error of 1 milligram per liter (mg/l), how many water specimens are required in the sample? assume that prior knowledge indicates that pollution readings in water samples taken during a day are approximately normally distributed with a standard deviation equal to 5 (mg/l).
Answers
Rounding up to the nearest whole number, we need a sample size of 25 water specimens to achieve a sampling error of 1 mg/L with 95% confidence.
To determine the number of water specimens required in the sample with a sampling error of 1 mg/L, we can use the formula:
n = (zα/2 * σ / E)^2
where:
n = the required sample size
zα/2 = the z-score associated with the level of confidence (for example, at 95% confidence, zα/2 = 1.96)
σ = the standard deviation of the pollution readings (given as 5 mg/L)
E = the desired sampling error (given as 1 mg/L)
Substituting the given values, we get:
n = (1.96 * 5 / 1)^2
n = 24.01
To learn more about deviation visit:
brainly.com/question/31835352
#SPJ11
Solve for z in terms of v, w, x, and y.
vy = -ZWx
Z =
I
Answers
Answer:
lots of letters
Step-by-step explanation: